
Quem poderia dizer não a um projeto que promete acesso à Internet para todas e todos? Starlink, uma constelação global de satélites de baixa órbita (LEO), dominou a imprensa em 2023 com anúncios do seu serviço em vários países africanos. Finalmente, banda larga para todos! Parece o caso perfeito de uma solução tecnológica que resolve um desafio antes insolúvel. Mas nem tudo pode ser o que parece.
Os desafios da transição ao IPv6
Por Geoff Huston autor e cientista chefe do APNIC*

Data da publicação:
Junho de 2013
Há uma falha grave na Internet de hoje. À primeira vista isso parece soar como uma contradição em termos, ou talvez uma frase de efeito para que você prossiga com a leitura. Afinal, a Internet é uma maravilha técnica dos dias de hoje. Em apenas duas décadas a Internet não só transformou o setor de comunicações global, como espalhou-se por nossa sociedade, modificando fundamentalmente o modo com que fazemos negócios, a natureza do entretenimento, a maneira com que compramos e vendemos, e até as estruturas de governos e seu relacionamento com os cidadãos. A Internet de vários modos tem provocado um efeito transformador em nossa sociedade - similar em escala e escopo ao da revolução industrial no século 19. Como seria possível que essa tecnologia prodigiosa da Internet esteja “gravemente defeituosa”? Tudo que funcionava ontem ainda está funcionando hoje, não é mesmo? Neste artigo procuro explicar esta situação com um pouco mais de detalhe e expor algumas rachaduras nas fundações da Internet de hoje.
Veja bem, as coisas dependem de endereços. Em uma rede de comunicações que permite comunicações individuais é essencial que todo ponto de destino na rede tenha seu endereço único. Na rede postal é comumente o endereço de seu domicílio. Na rede telefônica tradicional é o seu número telefônico. Esses endereços não são apenas a maneira pela qual outros usuários da rede podem escolher você, e só você, como o destinatário de suas comunicações. São também a maneira com que a rede em si pode assegurar que a comunicação é entregue corretamente ao destinatário pretendido. A Internet também usa endereços. Na verdade a Internet usa dois conjuntos de endereços.
Um conjunto de endereços é para o seu e o meu uso. Nomes de domínio são os endereços que digitamos em nossos navegadores Web, ou o que escrevemos do lado direito do “@” em um endereço de email. Esses endereços são como palavras em línguas naturais, o que facilita nosso uso. O outro conjunto de endereços é usado pela rede. Todo datagrama que passa pela Internet tem um campo em seu cabeçalho que descreve o endereço onde o datagrama deve ser entregue na rede: é o “endereço de destino”. Esse endereço é um valor de 32 bits. Um campo de dois bits tem dois valores possíveis, um campo de três bits tem oito valores possíveis, e um campo de 32 bits tem 2 elevado à 32ª potência, ou seja, 4.294.967.296 valores únicos.
Se todo dispositivo alcançável na Internet precisa de um endereço único para receber datagramas, isso significa que podemos interconectar no máximo cerca de quatro bilhões de dispositivos na Internet? Bem, em termos gerais, sim! E quando chegarmos a esse limite superior de endereços usados, devemos esperar problemas? Bem, em termos gerais, sim!
A falta de endereços disponíveis em qualquer rede de comunicações pode significar um grave problema. Já encontramos isso algumas vezes na rede telefônica, e a solução foi adicionar mais códigos de área, e em cada área acrescentar mais dígitos aos números telefônicos para acomodar um número cada vez maior de aparelhos telefônicos conectados. Todas as vezes que essas mudanças foram feitas na estrutura de endereçamento foi preciso reprogramar a rede. Por sorte, não foi preciso reprogramar os aparelhos telefônicos também. Bastava reeducar os usuários para que discassem mais dígitos. Com cuidado, paciência e recursos suficientes essa expansão do plano de endereçamento telefônico sempre pôde ser feita sem interrupção dos serviços e relativamente sem traumas.
Mas essa abordagem não se aplica à Internet. A estrutura de endereçamento da Internet não só é embutida nos dispositivos que operam a própria rede, como a mesma estrutura é embutida em qualquer dispositivo conectado à rede. Deste modo, se, ou melhor, quando terminarem aqueles endereços de 32 bits na Internet teremos que enfrentar o desafio gigantesco de não somente reprogramar cada componente da rede, como também reprogramar cada dispositivo a ela conectado. Lembrando que a Internet hoje tem mais de 2,3 bilhões de usuários e um número comparável de dispositivos conectados, isso soa como uma tarefa formidável e extremamente cara.
Se o término dos endereços IP disponíveis é um problema de tal magnitude para a Internet, é de se esperar que seja possível predizer quando esse evento desastroso ocorrerá, o que daria a todos nós tempo suficiente para pensar em algo inteligente como solução. E de fato essa exaustão de endereços foi prevista. Há cerca de 23 anos, em agosto de 1990, quando a Internet era em grande medida ainda um experimento científico e não a base fundacional de um grande empreendimento de comunicação global, foi feita a primeira predição de quando terminariam os endereços. Naquele tempo Frank Solensky, um participante da Força-tarefa de Engenharia da Internet (Internet Engineering Task Force, IETF), extrapolou o crescimento da Internet a partir do experimento emergente da rede NSFNet da Fundação Nacional de Ciências dos EUA, bem como de experimentos similares em outros projetos acadêmicos e de pesquisa, e previu que a reserva de endereços terminaria em cerca de seis a dez anos1. A comunidade técnica levou essa mensagem a sério e começou a trabalhar no problema no início dos anos 90.

Desse esforço surgiu uma solução provisória que, mesmo não resolvendo o desafio a longo prazo, poderia conseguir um precioso adiamento desse prazo. Na época, a Internet usava seus endereços de modo extremamente ineficiente. De modo similar ao de um plano de numeração telefônica que utiliza um código de área seguido de um número local, o plano de endereços da Internet divide um número IP em um identificador de rede e um identificador do hospedeiro (host) local. Na época tínhamos um plano de endereços que usava limites fixos entre a porção identificadora de rede e a porção identificadora do hospedeiro. Este plano foi uma variante da abordagem do tipo “tamanho único”, em que havia três tamanhos de endereços de hospedeiros: um tamanho era muito grande para a maioria das redes da Internet, outro era muito pequeno, e um terceiro era capaz de expandir a Internet para 16.382 redes. Foi este conjunto, o chamado grupo de blocos “Classe B”, que Frank Solensky previu que terminariam em quatro anos.
Qual foi então a solução provisória? Simples. Remover os limites fixos do plano de endereços e fornecer a cada rede da Internet somente a quantidade de endereços considerada necessária no momento para cada caso. Esperava-se que isso nos daria alguns anos mais para desenvolver uma resposta robusta de longo prazo para o problema. O novo plano de endereçamento foi ativado na Internet no início de 1993, e por alguns anos parecia que estaríamos bem. A figura 2 mostra que essa pequena mudança no plano de endereços, conhecida como Classless Inter-Domain Routing (CIDR), daria um tempo adicional de dois a três anos para se buscar uma resolução de longo prazo do problema da exaustão de endereços.
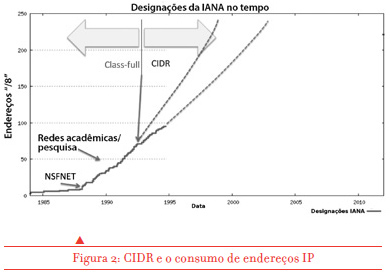
Mas o tempo mostrou que essa estimativa de mais dois ou três anos estava errada. A razão desse erro foi motivada por uma outra medida paliativa também desenvolvida no início dos anos 90. Essa nova tecnologia mexeu no coração da arquitetura da Internet e removeu a exigência estrita que todo dispositivo conectado deveria ter um endereço único na Internet.
A abordagem dos “tradutores de endereços de rede” (Network Address Translators, NATs) permitiu que um grupo de dispositivos compartilhasse um único endereço IP público. Os dispositivos localizados “por trás” de um NAT não poderiam ser o alvo de uma nova comunicação, ou seja, por exemplo, não seria possível hospedar um serviço Web por trás de um NAT, mas se os dispositivos por trás do NAT iniciassem as comunicações, a função NAT se tornaria invisível e o fato de que um mesmo endereço IP estava sendo compartilhado por vários dispositivos tornava-se efetivamente irrelevante. Em um modelo de clientes e servidores, se os clientes ficassem atrás de um NAT seria possível compartilhar um único endereço IP com todos os clientes simultaneamente.A nascente indústria de provedores de serviços Internet (ISPs) adotou a tecnologia do NAT com entusiasmo. O modelo de provisionamento para serviços Internet na ponta passou a utilizar um único número IP para cada serviço conectado, compartilhado por todos os computadores no domicílio por um NAT já incluido nos modems (DSL ou cabo) que fazem a interface entre a rede do usuário final à rede do provedor. A demanda por endereços IP com isso caiu dramaticamente, já que não era mais o caso de requerer um número IP para cada dispositivo conectado, mas apenas um único endereço IP para cada serviço conectado. O usuário conecta mais dispositivos, mas nenhum deles requer mais endereços IP do provedor.
Assim, em vez de estimar mais dois ou três anos de prazo para a exaustão de endereços, a combinação do CIDR com a tecnologia NAT levou a crer que o problema da exaustão estaria adiado por décadas! A previsão mais otimista da longevidade do estoque de endereços feita em torno de 2001 previu que este duraria algumas décadas, já que a curva de consumo de endereços ao longo do tempo tornou-se horizontal (figura 3).
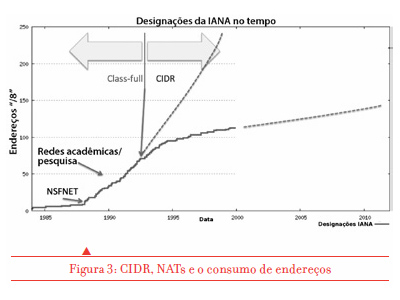
Com isso, a indústria pareceu colocar o assunto da exaustão de endereços Internet no topo de uma prateleira empoeirada no porão. Os eventos mostraram que essa complacência foi mal orientada. O impacto significativo seguinte no ambiente foi a revolução da Internet móvel na segunda metade da década de 2000. Até então os telefones móveis eram apenas telefones sem fio. Mas um dos principais provedores japoneses escolheu um caminho diferente, e a NTT DOCOMO lançou aparelhos móveis capazes de utilizar a Internet, que foram recebidos por um mercado entusiasmado no final dos anos 90. O crescimento rápido ano após ano dos serviços de Internet móvel despertou o interesse de provedores em outros países. E quando a Apple apresentou um dispositivo móvel que incluía uma tela relativamente grande e boa duração de bateria, uma impressionante coleção de aplicativos e, é claro, um módulo Internet completo, a situação mudou dramaticamente.
O iPhone foi rapidamente imitado por vários outros fabricantes e os operadores de serviços móveis embarcaram nas possibilidades desse novo mercado para serviços de Internet móvel. A expansão muito rápida desses serviços resultou em um forte crescimento da demanda por números IP para esses dispositivos móveis, e o quadro de exaustão de endereços mudou de novo. O que parecia ser um problema a ser considerado em um futuro mais distante tornou-se de novo um desafio quase imediato.
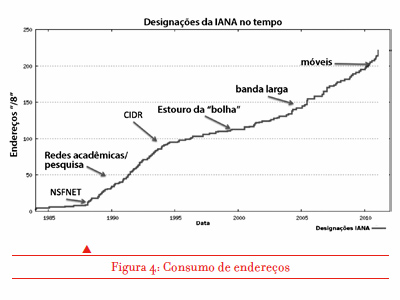
Mesmo assim, acabamos excedendo as expectativas mais otimistas e em vez de termos que enfrentar a exaustão do estoque de IPv4 em dois ou três anos, conseguimos empurrar o problema por mais uns 15 anos. Mas a pressão adicional da demanda por dispositivos móveis trouxe à cena a perspectiva de exaustão, e era chegada de novo a hora de encontrar uma solução de longo prazo. Qual era essa mesmo?
Durante os anos 90 a comunidade técnica não ficou satisfeita com as soluções paliativas. Levaram o assunto a sério e concluíram que era necessária uma nova arquitetura de rede de transmissão de dados por datagramas que poderia interconectar não bilhões, mas centenas de bilhões de dispositivos - ou ainda mais. Desse esforço surgiu a versão 6 do Protocolo Internet, ou IPv6. As mudanças em relação ao IPv4 foram relativamente conservadoras, exceto por uma mudança radical: os campos de endereço nos datagramas passaram a conter 128 bits, em vez de 32 bits. Toda vez que um novo bit é adicionado, dobra o número de endereços possíveis. Essa abordagem adicionou 96 bits ao plano de endereços IP. Isso significa 340.282.366.920.938.463.463.374.607.431.768.211.456 endereços possíveis – pouco mais de 340 mil decilhões de números únicos!
Esta abordagem para o IPv6 pareceu responder adequadamente à necessidade de uma substituição do sistema de numeração com endereços suficientes para alimentar uma voraz indústria do silício que pode produzir bilhões de processadores a cada ano. No entanto, há um problema residual que incomoda, resultante das características da arquitetura da Internet: o IP é um protocolo “ponta-a-ponta” (end-to-end): não há papel definido para os intermediários no processo de entrega de datagramas – o que é enviado em um datagrama é o que é entregue na outra ponta. Assim, se um dispositivo envia um datagrama IPv4 à rede, o que chega é um datagrama IPv4, não um datagrama IPv6. O resultado disso é que o IPv6 não é compatível com o IPv4. Em outras palavras, um dispositivo que envie ou receba dados no “novo” protocolo só pode comunicar-se com outro utilizando o mesmo protocolo. Este dispositivo fica completamente isolado da população existente de usuários da Internet. O que estavam pensando afinal esses técnicos ao oferecer um protocolo que não é interoperável com o existente?
Eles supunham que a indústria de serviços Internet é altamente avessa ao risco, e que uma vez que fosse definida uma tecnologia substituta de longo prazo, essa indústria começaria a trabalhar na sua ampla adoção bem antes do início da crise de exaustão dos atuais endereços. A ideia era que, bem antes do prazo previsto para a exaustão dos atuais endereços, todos os novos dispositivos Internet estariam configurados para operar em ambos protocolos, IPv4 e IPv6. A proposta era que esses dispositivos “bilíngues” tentariam primeiro comunicar-se em IPv6 e, caso não conseguissem, automaticamente mudariam para IPv4. A segunda parte do plano de transição era converter gradualmente a base instalada de dispositivos que só entendiam IPv4 e reprogramá-los para utilizar os dois, ou substitui-los se isso não fosse possível.
O plano de transição era simples. À medida que mais dispositivos na Internet fossem bilíngues, mais comunicações na rede usariam IPv6 em vez de IPv4. Ao longo do tempo o IPv4 basicamente morreria porque o suporte a esse protocolo já não seria mais necessário. No entanto, uma parte desse plano era crítica: teríamos que embarcar nele bem antes do prazo de exaustão dos endereços atuais e, mais criticamente ainda, teríamos que completar essa transição bem antes de utilizar o último endereço IPv4.
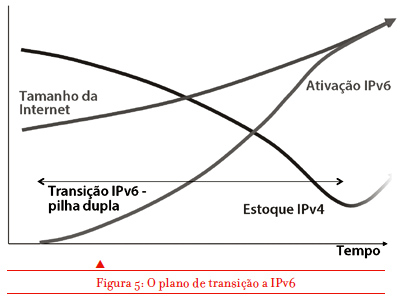
Em certa medida foi o que ocorreu. A Microsoft incluiu o IPv6 nos seus sistemas operacionais a partir de meados de 2000 com o Windows Vista e o Windows Server 2008. A Apple inclui o IPv6 no sistema operacional Mac OSX desde 2006. Mais recentemente, o suporte a IPv6 tem sido incluído em muitos dispositivos móveis. Atualmente estima-se que cerca da metade de todos os dispositivos conectados à Internet são bilíngues em IPv6 e IPv4. Essa é de fato uma conquista monumental, e muito do esforço de reprogramar os dispositivos conectados à Internet já foi conseguido. Estamos então prontos para virar a chave para o IPv6, certo? Não, de maneira nenhuma.
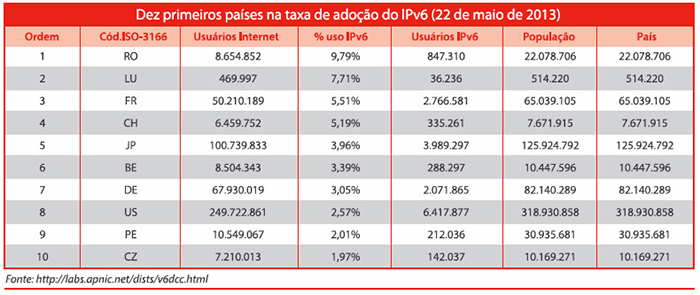
O que houve de errado? Muitas coisas não andaram de acordo com o plano, mas há dois aspectos da situação que precisam ser destacados. Em primeiro lugar, apesar da inclusão do IPv6 nas plataformas de computador mais populares, a adoção do IPv6 simplesmente não acontece. Se havia uma percepção que a adoção do IPv6 no início seria lenta, esperava-se que o uso do novo protocolo se acelerasse exponencialmente. Mas até agora não há evidências disso. Há muitos métodos de medição do processo de adoção do IPv6 na Internet, mas uma das mais úteis e relevantes é a que refere-se ao comportamento dos clientes. Quando apresentado a um serviço que está disponível tanto em IPv4 como IPv6, qual proporção de clientes prefere o IPv6? A Google fornece um ponto de medida, que avalia uma amostra de clientes do serviço Google.2
Ao longo dos últimos quatro anos a Google tem visto esse número crescer de menos de 1% dos usuários no começo de 2009 para um valor atual de 1,2%. Esta é uma daquelas histórias do copo meio cheio ou meio vazio. Só que neste caso o copo está 1% cheio ou 99% vazio! Se o plano é a adoção ampla do IPv6, estamos no momento muito longe dessa meta. Os dados por países mostram um quadro ainda mais desafiador. Só 11 países tiveram a porcentagem de usuários IPv6 acima de 1%, e a lista tem algumas surpresas (veja a tabela).
É difícil apresentar isso como evidência de adoção ampla do IPv6. Talvez seja mais acurado observar que um pequeno número de provedores tem sido ativo em oferecer IPv6 a seus clientes, mas esses provedores são uma minoria, e a maior parte da Internet continua presa fortemente ao IPv4. Se uma porcentagem significativa de dispositivos na ponta já suporta IPv6, por que essas porcentagens de utilização são tão inacreditavelmente baixas?
Parece que a outra parte do esforço de reprogramação da rede como um todo, aquela que envolve habilitar o IPv6 nos dispositivos localizados no interior da rede, não tem sido levada a efeito de modo significativo. Ainda é o caso que a grande maioria dos provedores não incluem IPv6 como parte de sua oferta de serviços – neste caso, mesmo que um computador ou dispositivo móvel seja capaz de “falar” IPv6, se o serviço de acesso não suportar o protocolo não há como usá-lo. E mesmo nos poucos casos em que o provedor fornece IPv6 como parte de sua gama de serviços, os equipamentos de rede do usuário, como os modems, roteadores, pontos de acesso wi-fi e outros, podem suportar somente IPv4. Até que esses equipamentos sejam substituídos ou atualizados, o IPv6 não vai acontecer. O resultado hoje é o que vimos: quando confrontados com a escolha entre IPv4 e IPv6, cerca de 99% dos dispositivos conectados à Internet só usam IPv4.
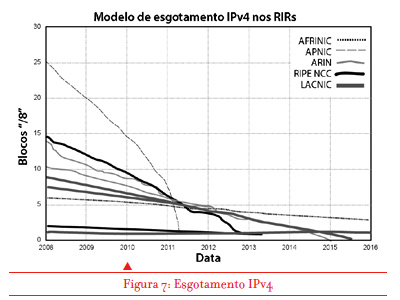
Em segundo lugar, acabamos de entrar no espaço que antes era visto como impensável: começam a faltar endereços IPv4 na rede atual. Essa exaustão começou com o estoque central de endereços, administrado pela Internet Assigned Numbers Authority (IANA). Esta entrega aos Registros Regionais de Números IP (conhecidos como RIRs) grandes blocos de endereços (16,777,216 endereços por “bloco”, cada um conhecido como ‘barra 8” ou “/8”), e em fevereiro de 2011 repassou aos RIRs os últimos grandes blocos. Cada um dos cinco RIRs opera de modo independente, e cada um deles enfrentará a exaustão de seus estoques IPv4 em resposta às demandas de suas regiões.
O APNIC, o RIR que serve a região da Ásia e Pacífico, foi o primeiro a esgotar seu estoque – em abril de 2011 entregou seu penúltimo bloco IPv4 aos provedores da região. Restou um último que é distribuído restritamente em pequenos blocos de 1.024 endereços a cada solicitante. Isto representa uma mudança abrupta na região. No último ano em que os endereços foram distribuídos normalmente para uso geral, 2010, o APNIC entregou cerca de 120 milhões de endereços. Em 2012, o primeiro ano de operação com apenas esse último “/8”, o número total de endereços distribuídos caiu para um milhão. A demanda não satisfeita na região parece crescer em torno de 120 a 150 milhões de endereços por ano.
A região da Europa e Oriente Médio veio a seguir: em setembro de 2012 o registro regional, RIPE NCC, também chegou a seu último “/8” e suspendeu a distribuição de IPv4 para uso geral. O processo de exaustão continua, e o registro que serve a América do Norte e partes do Caribe (ARIN) tem cerca de 40 milhões de endereços em estoque. Na atual taxa de distribuição, deverá chegar ao seu último “/8” em abril de 2014. LACNIC, o registro latino-americano e caribenho, tem atualmente cerca de 32 milhões de endereços e projeta chegar ao último “/8” em agosto de 2014. Por fim, o registro africano AFRINIC, com 62 milhões de endereços, é o melhor situado, devendo ser exaurido em cerca de sete anos.
Deste modo, se o conceito era que não somente começaríamos, mas completaríamos o processo de transição para usar IPv6 na Internet como um todo antes que chegássemos a usar o último endereço IPv4, então para a Europa, o Oriente Médio, a Ásia e o Pacífico isso não vai mais ocorrer. É tarde demais. E para as Américas também é muito difícil que ocorra a tempo. A lenta adoção do IPv6 aponta para a expectativa que esta condição de “rodar com o tanque vazio” para o plano de endereços pode continuar por alguns anos mais. Estamos entrando em um período de dano potencial para a Internet. Se o objetivo dessa transição de IPv4 a IPv6 era evitar algumas das piores falhas do esgotamento do estoque de endereços IPv4, então nós fracassamos.
A consequência desse fracasso é que estamos agora trazendo um novo desafio para a Internet. Já é um dado concreto que será preciso enfrentar um crescimento continuado e em aceleração em termos do tamanho da rede como um todo e da população de dispositivos conectados. O ritmo desse crescimento pode ser medido por uma demanda de cerca de 300 milhões de novos endereços IP por ano, e os números dos fabricantes apontam para 500 a 700 milhões de novos dispositivos sendo conectados à Internet anualmente. A tendência desses números é aumentar a cada ano. A Internet está se expandindo a taxas ainda mais altas. Como se não bastasse o desafio de ter que enfrentar essa taxa fenomenal de crescimento contando com a base tecnológica e de infraestrutura existente, temos ainda o objetivo não só de manter, mas de acelerar o ritmo de transição ao IPv6.
Essas duas tarefas já estavam sendo extremamente difíceis, e estamos patinando na segunda. Mas agora temos o desafio adicional de tentar satisfazer esses dois objetivos sem estoque de endereços IPv4. Neste ponto o grau de dificuldade começa a ficar muito próximo de dez!
Esta situação apresenta algumas consequências arquiteturais para a Internet. Até agora conseguimos manter os NATs nas bordas da rede, controlando o consumo de endereços nas redes dos usuários. As consequências das falhas desses dispositivos e funções ficam limitadas à rede na ponta servida pelo NAT. Agora estamos ativando mecanismos que permitem o uso da função NAT no núcleo das redes de transporte de dados. Isso introduz um novo conjunto de fatores ainda não quantificados. Temos pouca experiência em trabalhar com NAT em grandes redes. Não temos ideia dos tipos de falhas, ou mesmo do conjunto de vulnerabilidades nessa abordagem.
Ainda estamos debatendo a abordagem técnica mais apropriada nos organismos de padronização, e assim há uma variedade de abordagens para o serviço NAT no nível dos provedores. Cada abordagem tem propriedades operacionais distintas e diferentes aspectos de segurança. Mas agora não podemos dar-nos mais ao luxo de conseguir mais tempo para explorar as várias alternativas e entender as qualidades e fraquezas relativas de cada uma. As exigências provocadas pelo esgotamento de endereços torna urgente a necessidade de adotar soluções do tipo NAT no nível dos provedores de acesso, e nessa situação que não pensávamos experimentar, estamos mal preparados par lidar com os efeitos colaterais dessa mudança sutil na arquitetura da rede. O maior nível de complexidade que acrescentamos à rede e a variação mais ampla de comportamentos decorrentes disso aumenta o fardo sobre as aplicações. Se a negociação de tráfego torna-se mais complexa na rede, as aplicações são forçadas a explorar mais as propriedades locais do ambiente de rede para seguir garantindo ao usuário uma qualidade de serviço robusta.
Se a característica central da Internet era de eficiência e flexibilidade baseada em uma arquitetura de rede simples, ao acrescentarmos complexidade à rede perdemos essa mesma eficiência e flexibilidade que tornaram a Internet tão sedutoramente atrativa em primeiro lugar. O resultado é uma rede recheada de ornamentos que comporta-se de maneiras cada vez mais caprichosas.
Estamos inevitavelmente viciados no uso de um protocolo de rede que agora está sem endereços disponíveis. Neste ponto, o futuro da Internet, com suas projeções de valor de trilhões de dólares, com suas projeções de bilhões de dispositivos de silício a ela conectados, com suas projeções de petabytes de tráfego, com suas projeções de oferta de fibra generalizada em todo o mundo, entra agora em um período de extrema incerteza e confusão. Um caminho de evolução para um novo protocolo bem planejado que poderia equacionar esses potenciais futuros confortavelmente já não está sendo seguido. A infraestrutura de endereços que sustenta a rede é agora sujeita à escassez em vez de abundância, e isso está tendo implicações profundas na evolução da Internet.
Há realmente uma falha grave na Internet hoje.
Originalmente publicado em inglês em abril de 2013 em http://www.circleid.com/posts/20130421_a_primer_on_ipv4_ipv6_and_transition
* As opiniões neste artigo não necessariamente representam as do APNIC.
---
1. A figura 1 é o relatório escrito à mão de Frank Solensky sobre Exaustão de Endereços, Proceedings of IETF 18, p. 61, Vancouver, agosto de 1990.
2. Os resultados podem ser vistos em https://www.google.com/ipv6/statistics.html
Categoria:


{kind=link}